
How to Create Effective a Self-Contained Docker Cluster
A self-sufficient system is one that is able to recover and adapt. Restoration means that the cluster will almost always be in the state in which it was projected.
For example, if a copy of the service fails, the system will need to restore it.
- Adaptation is related to the modification of the desired state so that the system can cope with the changed conditions. A simple example would be an increase in traffic. In this case, the services need to be scaled. When recovery and adaptation are automated, we get a self-healing and self-adapting system. Such a system is self-sufficient and can operate without human intervention.
- What does a self-contained system look like?
- What are its main parts?
- Who are the actors?
In this article, we will discuss only the services and ignore the fact that hardware is also very important. With such limitations, we will compose a high-level picture that describes (basically) an autonomous system in terms of services. We will omit the details and take a look at the system from a bird’s eye view.
If you are well versed in the topic and want to understand everything at once, the system is depicted in the figure below.
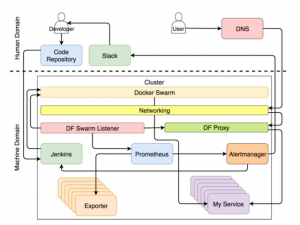
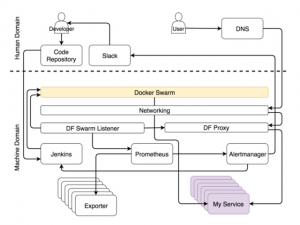
- We can divide the system into two main areas – human and machine.
- The same thing is happening now with modern clusters. The majority treats them, as if in the yard of 1999. Virtually all actions are performed manually, the processes are cumbersome, and the system survives only due to brute force and wasted energy. Some realized that the yard was already in 2017 (at least at the time of writing this article) and that a well-designed system should perform most of the work autonomously. Almost everything should be driven by machines, not by humans.
- But this does not mean that there is no room left for people. Work for us still exist, but it is more connected with creative and non-repeating tasks. Thus, if we focus only on cluster operations, the human area of responsibility will decrease and give way to machines. Tasks are distributed by roles. As you will see below, the specialization of the tool or the person can be very narrow, and then he will perform only one type of tasks, or he can be responsible for many aspects of operations.
The role of the developer in the system
The human responsibility area includes processes and tools that need to be managed manually. From this area, we try to remove all repetitive actions. But this does not mean that it should disappear altogether. Quite the contrary. When we get rid of repetitive tasks, we free up time that can be spent on really meaningful tasks. The less we deal with tasks that can be delegated to a machine, the more time we can spend on those tasks for which creativity is required.
- This philosophy stands in line with the strengths and weaknesses of each actor of this drama. The machine is well controlled with numbers. They are able to perform the given operations very quickly. In this matter, they are much better and more reliable than we are. We, in turn, are able to think critically. We can think creatively. We can program these machines. We can tell them what to do and how.
- We appointed the developer the main character in this drama. We deliberately refused the word “coder”. The developer is any person who is working on a software development project. It can be a programmer, a tester, an operations guru, or a scrum-master – it’s all not important. I put all these people in a group called a developer. As a result of their work, they must place some code in the repository. While he is not there, he supposedly does not exist. It does not matter whether it is on your computer, laptop, desk or on a small piece of paper attached to the mail pigeon. From the system’s point of view, this code does not exist until it reaches the repository. I hope this repository is Git, but, in theory, it can be any place where you can store anything and track versions.
- This repository also falls within the area of human responsibility. Although this software, it belongs to us. We work with him. We update the code, download it from the repository, merge its parts together and sometimes come to the horror of the number of conflicts. But we can not conclude that there are no automated operations at all, nor that some areas of machine responsibility do not require human intervention. And still, if in some area most of the tasks are done manually, we will consider it to be the area of human responsibility. The code repository is definitely part of the system that requires human intervention.

Let’s see what happens when the code is sent to the repository.
The role of continuous deployment in the system
The process of continuous deployment is fully automated. No exceptions. If your system is not automated, then you do not have a continuous deployment. You may need to manually debug in production. If you manually click on one single button, in which bold is written “deploy”, then your process is a continuous delivery. This we can understand. This button may be required from the point of view of the business. And yet the level of automation, in this case, is the same as for continuous deployment. You are only here making decisions. If you want to do something else manually, then you either perform continuous integration or, more likely, do something that does not have the word “continuous” in its title.
- It does not matter whether it is a continuous deployment or delivery, the process should be fully automated. All manual actions can be justified only by the fact that you have an outdated system that your organization prefers not to touch (usually this application is on Kobol). It just stands on the server doing something. I really like the rules like “no one knows what it does, so it’s better not to touch it.” This is the way to express the greatest respect while maintaining a safe distance. And yet we will assume that this is not your case. You want to do something with it, the desire literally rips you to pieces. If this is not the case, and you were not lucky enough to work with the system “hands off from here,” then you should not read this article.
- Once the repository receives a commit or pulls request, the Web hook is triggered, which in turn sends the request to the continuous deployment tool to start the continuous deployment process. In our case, this tool is Jenkins. The request starts a thread of all sorts of tasks for continuous deployment.
- It checks the code and conducts unit tests.
- It creates the image and puts it in the register.
- It runs functional, integration, load, and other tests – those that require a working service.
- At the very end of the process (not including tests), the query is sent to the scheduler to deploy or update the service in the cluster. Among other planners, we choose Docker Swarm.
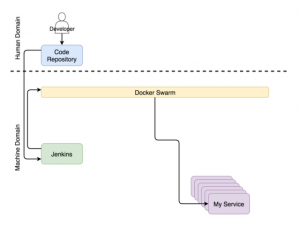
Simultaneously with the continuous deployment, another set of processes works, which monitor the updates of the system configurations.
The role of service configuration in the system
Whichever element of the cluster is changed, you need to reconfigure some parts of the system. You may need to update the proxy configuration, the metrics collector may need new targets, the log parser – update the rules.
- It does not matter which parts of the system need to be changed, most importantly – all these changes should be applied automatically. Few people will argue with this. But there is a big question: where do you find those parts of the information that should be introduced into the system? The most optimal place is the service itself. Because Almost all planners use Docker, it’s more logical to store information about the service in the service itself in the form of labels. If we post this information elsewhere, we will lose a single truthful source and it will become very difficult to perform auto-detection.
- If the service information is inside it, this does not mean that the same information should not be placed elsewhere inside the cluster. It follows. However, the service is the place where the primary information should be, and from now on it must be transferred to other services. With Docker, it’s very simple. He already has an API to which anyone can connect and get information about any service.
There is a good tool that finds information about the service and distributes it throughout the system – the Docker Flow Swarm Listener (DFSL). You can use any other solution or create your own. The ultimate goal of this and any other such tool is to listen to Docker Swarm events. If the service has a special set of shortcuts, the application will receive the information as soon as you install or update the service. After that, it will pass this information to all interested parties. In this case, this is the Docker Flow Proxy (DFP, inside of which there is HAProxy) and the Docker Flow Monitor (DFM, inside there is Prometheus). As a result, both will always have the latest actual configuration. The proxy has a way to all public services, whereas Prometheus has information about exporters, alerts, Alertmanager address and other things.

While there are deployment and reconfiguration, users should have access to our services without downtime.
The role of Proxy in the system
Each cluster must have a proxy that will accept requests from a single port and redirect them to the designated services. The only exception to the rule will be public service. For such a service, the question is not only the need for a proxy, but for a cluster in general. When a request comes into the proxy, it is evaluated and, depending on its path, the domain and some headers are redirected to one of the services.
- Thanks to Docker, some aspects of the proxy are now obsolete. You no longer need to balance the load. The Docker Overlay network does this for us. It is no longer necessary to support the IP-nodes on which services are hosted. Service discovery does this for us. All that is required from the proxy is to evaluate the headers and forward the requests to where they should go.
- Because Docker Swarm always uses sliding updates, when any aspect of the service changes, the continuous deployment process should not cause downtime. In order for this statement to be true, several requirements must be met. At least two replicas of the service should be launched, and better still more. Otherwise, if there is only one replica, the simple is inevitable. For a minute, a second or a millisecond, it does not matter.
Simple does not always cause a disaster. It all depends on the type of service. When Prometheus is updated, you can not escape from idle time, because the program can not scale. But this service can not be called public unless you have several operators. A few seconds of idle will not harm anyone.
- It’s quite another matter – a public services like a large online store with thousands or even millions of users. If such a service crouches, then it will quickly lose its reputation. We, consumers, are so spoiled that even a single glitch will force us to change our point of view and go looking for a replacement. If this malfunction continues, again and again, the loss of business is almost guaranteed. Continuous deployment has many advantages, but since it is used quite often, there are more and more potential problems, and a simple one is one. In fact, you can not allow downtime in one second, if it repeats several times a day.
There is good news: if you combine rolling updates and multiple replicas, you can avoid downtime, provided that the proxy is always the latest version.
- If we combine duplicate updates with a proxy that dynamically reconfigures itself, we get a situation where the user can at any time send a request to the service and it will not be affected by either continuous deployment, failure, or any other changes in the state of the cluster. When a user sends a request to a domain, this request penetrates the cluster through any working node, and it is intercepted by the Ingress Docker network. The network, in turn, determines that the request uses the port on which the proxy listens and forwards it there. The proxy, on the other hand, evaluates the path, domain and other aspects of the request and forwards it to the designated service.
We use the Docker Flow Proxy (DFP), which adds the necessary level of dynamics over HAProxy.

The next role that we will discuss is related to the collection of metrics.
The role of metrics in the system
Data is a key part of any cluster, especially one that is aimed at self-adaptation. Hardly anyone will argue that we need both past and current metrics. Happens that, without them, we’ll run like that cock in the yard, to whom the cook cut off his head. The main question is not whether they are necessary, but what to do with them. Typically, operators with an endless clock stare at the monitor. This approach is far from effective. Look better at Netflix. They at least approach the issue of fun. The system must use metrics. The system generates them, collects and decides what actions to take when these metrics reach certain thresholds. Only then can the system be called self-adapting. Only when it acts without human intervention, they are self-sufficient.
- A self-adapting system must collect data, store it, and apply various actions to it. We will not discuss what is better – sending data or collecting it. But since we use Prometheus to store and evaluate data, and to generate alerts, we will collect data. This data is available from exporters. They can be common (for example, Node Exporter, advisor, etc. or specific to the service. In the latter case, services should provide metrics in a simple format that Prometheus expects.
- Regardless of the threads that we described above, exporters issue different types of metrics. Prometheus periodically collects them and stores them in the database. In addition to gathering metrics, Prometheus also continuously evaluates the thresholds set by the alert, and if the system reaches one of them, the data is transferred to the Alert manager. In most cases, these limits are reached when conditions change (for example, the load of the system has increased).

The role of alerts in the system
Alerts are divided into two main groups, depending on who gets them – the system or the person. When an alert is evaluated as a system alert, the request is usually sent to the service, which is able to assess the situation and perform the tasks that will prepare the system. In our case, this is Jenkins, which performs one of the predefined tasks.
- The most frequent tasks that Jenkins performs are usually to scale (or unscramble) the service. However, before he attempts to scale, it needs to know the current number of replicas and compare them with the higher and lower limit, which we asked with the help of shortcuts. If based on the results of the scaling, the number of replicas goes beyond these limits, it will send a notification to Slack so that the person decides what actions to take to solve the problem. On the other hand, when the number of replicas is maintained within the specified limits, Jenkins sends a request to one of the Swarm managers, which in turn increases (or decreases) the number of replicas in the service. This process is called self-adaptation because the system adapts to changes without human intervention.
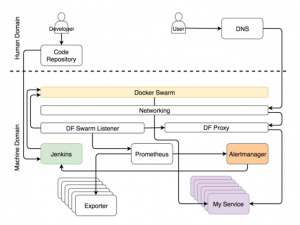
- Although our goal is a completely autonomous system, in some cases a person can not do without. In fact, these are cases that can not be foreseen. When something happens that we expected, let the system eliminate the error. A person should be called only when surprises happen. In such cases, Alertmanager sends a notification to the person. In our version, this is a notification via Slack, but in theory, it can be any other service for sending messages.
- When you start designing a self-healing system, most notifications will fall into the category “unexpected.” You can not predict all situations. The only thing you can do in this case is to make sure that the unexpected happens only once. When you receive a notification, your first task is to manually adapt the system. The second is to improve the rules in Alertmanager and Jenkins so that when the situation recurs, the system could cope with it automatically.
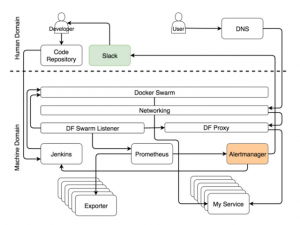
Setting up a self-adapting system is hard, and this work is endless. It constantly needs to be improved. And what about self-healing? Is it difficult to achieve it?
The role of the scheduler in the system
Unlike self-adaptation, self-healing is relatively easy to achieve. While there are enough resources, the scheduler will always follow to ensure that a certain number of replicas work. In our case, this is the Docker Swarm schedule.
- Replicas can fail, they can be killed and they can be inside an unhealthy node. This is not so important, as Swarm makes sure that they restart if necessary and (almost) always work normally. If all our services are scalable and at least a few replicas are running on each of them, there will never be any downtime. Self-healing processes within the Docker will make self-adaptation processes easily accessible. It is the combination of these two elements that make our system completely autonomous and self-sufficient.
- Problems start to accumulate when the service can not be scaled. If we can not have several replicas of the service, Swarm can not guarantee the absence of downtime. If the replica fails, it will be restarted. However, if this is the only available replica, the period between the accident and the restart is turned into a simple one. People all the same. We fall ill, we lie in bed and after a while, we return to work. If we are the only employee in this company and we have no one to replace, while we are absent, then this is a problem. The same applies to services. For a service that wants to avoid downtime, you must at least have two replicas.
- Unfortunately, our services are not always designed with scalability. But even when it is taken into account, there is always a chance that it does not belong to any of the third-party services that you use. Scalability is an important design decision, and we must take this requirement into account when we choose a new tool. We must clearly distinguish between services for which a simple is unacceptable and services that do not expose the system to risk if they are unavailable for a few seconds. Once you learn to distinguish between them, you will always know which of the services are scalable. Scalability is the requirement of unsupported services.
The role of the cluster in the system
In the end, everything we do is inside one or more clusters. There are no more individual servers. We do not decide where to send. This is done by planners. From our (human) point of view, the smallest object is a cluster in which resources like memory and CPU are gathered.





{kind=link}