
How to create a ChatBot using sockeye (MXNet) based on AWS EC2 and AWS DeepLearning AMI
Recently, the AWSDeepLearning team has released a new framework called “sockeye“, whose goal is to simplify the learning of seq2seq networks. Looking ahead – I did not even expect such simplicity.
- So we decided to write a simple, quick and self-sufficient guide that does not require the reader to have a deep knowledge of neural networks. The only thing that is still required for the successful execution of all steps is to have some experience with:
- Despite the fact that officially this framework is designed for network training, for machine translation, technically it can also be used to train a more general class of tasks of converting one sequence to another (seq2seq).
- We already touched on the topic of why machine translation and the creation of chat bots, like two tasks, have a lot of similarities and can be solved in a similar way, in one of the previous articles.
- So, we will not repeat ourself’s, leaving the opportunity for inquisitive readers to go through the links, and in the meantime, we will go directly to creating a chatbot.
Process description
In general, the process consists of the following steps:
- Raise EC2 machine with GPU based on DeepLearning AMI;
- Prepare an EC2 machine for training;
- Start training;
- Wait;
- Profit;
Now, let raise EC2 machine with GPU, based on AWS DeepLearning AMI
- In this article, we will use AWS DeepLearning AMI, hereinafter: DLAMI (by the way, if you do not know what AMI is, then I recommend that you read the official documentation here). The main reasons for using this particular AMI are:
- It includes Nvidia CUDA drivers (at the time of this writing, version: 7.5);
- Assembled with GPU support – MXNet;
- Includes all (almost) utilities that we need, for example, git;
- Can be used with, surprise-surprise, machines in which there is a GPU.
- In order to quickly create the desired machine from AMI, go to the page DLAMI in the AWS Marketplace. Here you should pay attention to the following things:
1. AMI version

- At the time of writing, “Jun 2017” was the latest version, so if you want your process to be a consistency with the rest of this article, I recommend that you select it.
2. Region for creation

- Note that not all types of machines with GPU are available in all regions. Actually, even if they are formally available, it is not always possible to create them. So, for example, in 2016 during the NIPS conference with them was very problematic. We need a p2-type machine, plus, and at the time of writing, DLAMI was only available in regions where this type was available:

3. Instance Type Selection
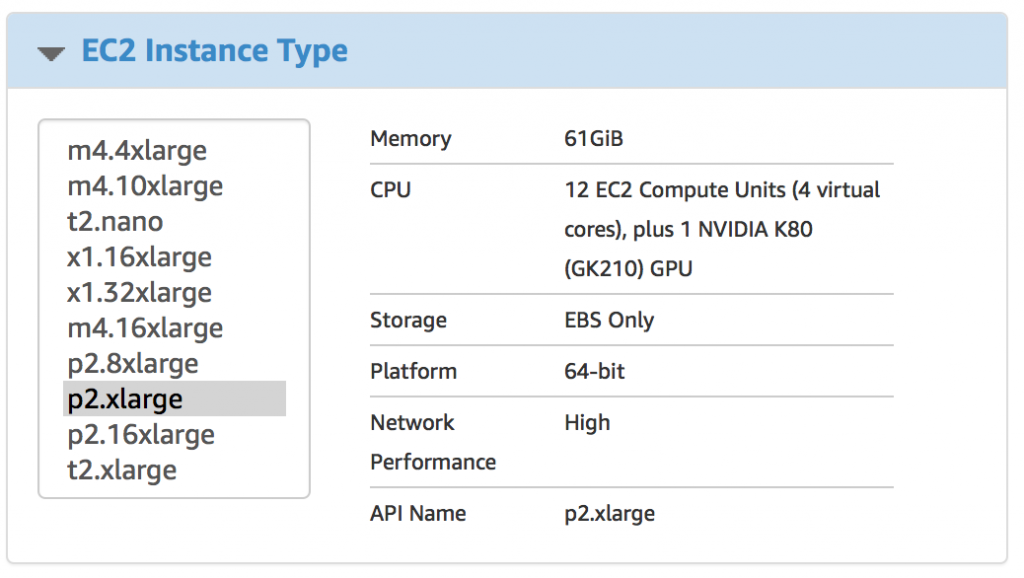
- P2.xlarge – is the cheapest machine that meets our requirements for GPU memory (you can certainly try and g2.2xlarge, but do not say then that you were not warned). At the time of writing, the price for it was ~ $ 0.9 per hour. But better check the price on the official website.
4. VPC

If you do not know how to work with it – better don’t even touch it.
5. Security Group

- As well as with VPC, do not know – better do not touch. However, if you want to use an existing group, then make sure that SSL is open.
6. Key pair

- Let me assume that you are as the reader has experience with SSH and have a clear understanding of what it is.
7. Waiting for Creation

Actually now we can create a VM and connect to it.
Preparing for Network Training
- Connect to the newly created VM. Right after, it’s time to start the screen. And do not forget the fact that when connecting you need to use the ec2-user login:
![]()
A few remarks at this point:
- Machine with this IP is no longer in the network so do not try to ping it;
- I said “screen” because DLAMI does not contain tmux from the box;
- If you do not know what screen or tmux is – no problem, you can just continue reading, everything will work without problems. However, it’s better to go and read about what these animals are: tmux (my choice) and screen.
1. installing sockeye
- The first thing we need is to install sockeye. With DLAMI, the installation process is very simple, with just one command:
sudo pip3 install sockeye --no-deps
- The important thing here is that you need to use pip3, not just pip because by default pip from DLAMI uses Python 2, which in turn is not supported in red. There is also no need to set any dependencies for them all are already installed.
2. Preparation of data (dialogues) for training
For training, we will use “Cornell Movie Dialogs Corpus” (https://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html). This, in fact, a huge body of dialogues from the films.
Well, let’s prepare the data for training:
# cd ~/src src# git clone https://github.com/b0noI/dialog_converter.git Cloning into ‘dialog_converter’… remote: Counting objects: 59, done. remote: Compressing objects: 100% (49/49), done. remote: Total 59 (delta 33), reused 20 (delta 9), pack-reused 0 Unpacking objects: 100% (59/59), done. Checking connectivity… done. src# cd dialog_converter dialog_converter git:(master)# git checkout sockeye_chatbot Branch sockeye_chatbot set up to track remote branch sockeye_chatbot from origin. Switched to a new branch 'sockeye_chatbot' dialog_converter git:(sockeye_chatbot)# python converter.py dialog_converter git:(sockeye_chatbot)# ls LICENSE README.md converter.py movie_lines.txt train.a train.b test.a test.b
A couple of things that you should pay attention to:
- The src folder already exists, there is no need to create it;
- Note the brunch: “sockeye_chatbot“, in it I store the code that is consistent with this article. Use the master at your own peril and risk.
Now let’s create a folder where we will conduct training and copy all the data there:
# cd ~ # mkdir training # cd training training# cp ~/src/dialog_converter/train.* . training# cp ~/src/dialog_converter/test.* .
Well, everything is ready to start a training.
Training
- With sockeye, the learning process is very simple – you just need to run one single command:
python3 -m sockeye.train --source train.a --target train.b --validation-source train.a --validation-target train.b --output model
I know, NEVER use the same data for training and validation. However, my script at the moment does not quite correctly break the data into two groups and therefore better results (I’m on subjective estimation) are obtained, as it is not strange, without breakdown.

Sockeye tries for you to find a suitable configuration for training, namely:
- The size of the dictionary;
- Network parameters;
etc.…
- This is pretty good since a configuration that is closer to the optimum can lead to a faster (read a cheaper) workout. Although still need to see how exactly sockeye performs a search for parameters and how much resources are spent on this process.
- Also, sockeye will determine when the training process should be completed. This will happen if the quality of the model has not improved on the data for validation for the last 8 control points.
Waiting for the result
- While waiting, you can see how MXNet is taking GPU resources during training. To do this, you need to run this command in a new window:
watch -n 0.5 nvidia-smi
You have to see something like that:

- By the way, technically, to start communication with the bot, you just need to wait at least the first checkpoint created. When this happens you will see something like this:

Now you can start communication.
Starting a chat
- This process does not require stopping training, you just need to open a new window (well, or a new SSH connection) go to the same folder where the training takes place and execute the command:
python3 -m sockeye.translate --models model --use-cpu --checkpoints 0005
There are some elements that I want to focus on:
- Python3;
- Model – the name of the folder in which the learning process saves the model, must match the name specified during the training;
- –use-CPU – without this MXNet will try to use the GPU that will most likely result in failure as the learning process still uses it.
- –checkpoints 0005 – the number of the control point, is taken from the console output when the checkpoint is saved.
- After running the command, sockeye will read the input from STDIN and output the response to STDOUT. Here are some examples:
After an hour of training:

After 2 hours of training:

After 3 hours of training, it began to threaten me:

Conclusion
As you can see that with sockeye, the learning process is very simple. Actually, the most difficult part is boot up the right VM and connect to it.
From the link bellow you can download a completed ChatBot:


{kind=link}