The Neural Network For C ++ Developers!
Hello guys.
I’ve recently written a library for learning neural network. Who interested, please welcome.
I have long wanted to make myself a tool of this level. Since this summer took up the case. Here’s what happened:
- The library is written from scratch in C++ (only STL + OpenBLAS for calculation), C-interface, Windows/Linux;
- The network structure is set in JSON;
- A base layers: fully connected, convolutional, pooling. Additional: resize, crop;
- A basic chips: batchNorm, dropout, scales optimizers – Adam, adagrad;
- OpenBLAS is used for calculation on the CPU and CUDA/cuDNN for the video card. Laid another implementation on OpenCL, while for the future;
- For each layer there is an opportunity to separately set on what to count – CPU or GPU (and which one);
- The size of the input data is not strictly specified, it may change in the process of work/training;
- I’ve made interfaces for C ++ and Python. C# will be later too.
I’ve called the library the “SkyNet“.
Comparing with “PyTorch” using the MNIST example:
- PyTorch: Accuracy: 98%, Time: 140 sec
- SkyNet: Accuracy: 95%, Time: 150 sec
Machine: i5-2300, GF1060 – test code.
Software architecture
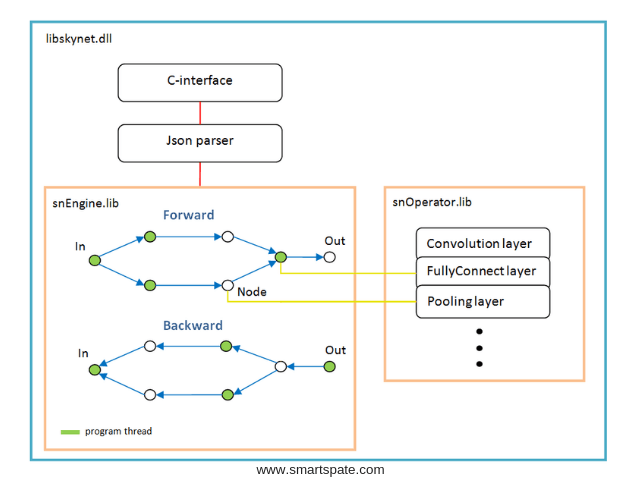
The basis of the operations graph is created dynamically once after analyzing the network structure.
For each branching – a new stream. Each network node (Node) is a calculation layer.
There are features of work:
- The activation function, batch normalization, dropout — they are all implemented as parameters of specific layers, in other words, these functions do not exist as separate layers. Perhaps batchNorm should be separated into a separate layer in the future;
- The softMax function is also not a separate layer, it belongs to the special layer “LossFunction”. In which it is used when choosing a specific type of error calculation;
- The “LossFunction” layer is used to automatically calculate the error, those obviously cannot use the steps forward / backward (below is an example of working with this layer);
- There is no “Flatten” layer, it is not needed because the “FullyConnect” layer itself pulls the input array;
- Weights optimizer must be set for each weight layer, by default ‘Adam’ is used for all.
Examples
MNIST

The C++ code looks like this:
// network creation
sn :: Net snet;
snet.addNode ("Input", sn :: Input (), "C1")
.addNode ("C1", sn :: Convolution (15, 0, sn :: calcMode :: CUDA), "C2")
.addNode ("C2", sn :: Convolution (15, 0, sn :: calcMode :: CUDA), "P1")
.addNode ("P1", sn :: Pooling (sn :: calcMode :: CUDA), "FC1")
.addNode ("FC1", sn :: FullyConnected (128, sn :: calcMode :: CUDA), "FC2")
.addNode ("FC2", sn :: FullyConnected (10, sn :: calcMode :: CUDA), "LS")
.addNode ("LS", sn :: LossFunction (sn :: lossType :: softMaxToCrossEntropy),
"Output");
............. // image acquisition-preparation
// learning cycle
for (int k = 0; k <1000; ++ k) {
targetLayer.clear ();
srand (clock ());
// fill the batch
for (int i = 0; i <batchSz; ++ i) {
.............
}
// call network training method
float accurat = 0;
snet.training (lr, inLayer, outLayer, targetLayer, accurat);
}
The full code is available here. Some pictures added to the repository, are next to the example. I used OpenCV for reading images, it did not include it in the kit.
Another network of the same plan, more difficult.

The code for creating such a network is:
// network creation
sn :: Net snet;
snet.addNode ("Input", sn :: Input (), "C1 C2 C3")
.addNode ("C1", sn :: Convolution (15, 0, sn :: calcMode :: CUDA), "P1")
.addNode ("P1", sn :: Pooling (sn :: calcMode :: CUDA), "FC1")
.addNode ("C2", sn :: Convolution (12, 0, sn :: calcMode :: CUDA), "P2")
.addNode ("P2", sn :: Pooling (sn :: calcMode :: CUDA), "FC3")
.addNode ("C3", sn :: Convolution (12, 0, sn :: calcMode :: CUDA), "P3")
.addNode ("P3", sn :: Pooling (sn :: calcMode :: CUDA), "FC5")
.addNode ("FC1", sn :: FullyConnected (128, sn :: calcMode :: CUDA), "FC2")
.addNode ("FC2", sn :: FullyConnected (10, sn :: calcMode :: CUDA), "LS1")
.addNode ("LS1", sn :: LossFunction (sn :: lossType :: softMaxToCrossEntropy),
"Summ")
.addNode ("FC3", sn :: FullyConnected (128, sn :: calcMode :: CUDA), "FC4")
.addNode ("FC4", sn :: FullyConnected (10, sn :: calcMode :: CUDA), "LS2")
.addNode ("LS2", sn :: LossFunction (sn :: lossType :: softMaxToCrossEntropy),
"Summ")
.addNode ("FC5", sn :: FullyConnected (128, sn :: calcMode :: CUDA), "FC6")
.addNode ("FC6", sn :: FullyConnected (10, sn :: calcMode :: CUDA), "LS3")
.addNode ("LS3", sn :: LossFunction (sn :: lossType :: softMaxToCrossEntropy),
"Summ")
.addNode ("Summ", sn :: Summator (), "Output");
In the examples it is not, you can copy from here.
In Python, the code also looks like:
// network creation
snet = snNet.Net ()
snet.addNode ("Input", Input (), "C1 C2 C3") \
.addNode ("C1", Convolution (15, 0, calcMode.CUDA), "P1") \
.addNode ("P1", Pooling (calcMode.CUDA), "FC1") \
.addNode ("C2", Convolution (12, 0, calcMode.CUDA), "P2") \
.addNode ("P2", Pooling (calcMode.CUDA), "FC3") \
.addNode ("C3", Convolution (12, 0, calcMode.CUDA), "P3") \
.addNode ("P3", Pooling (calcMode.CUDA), "FC5") \
\
.addNode ("FC1", FullyConnected (128, calcMode.CUDA), "FC2") \
.addNode ("FC2", FullyConnected (10, calcMode.CUDA), "LS1") \
.addNode ("LS1", LossFunction (lossType.softMaxToCrossEntropy), "Summ") \
\
.addNode ("FC3", FullyConnected (128, calcMode.CUDA), "FC4") \
.addNode ("FC4", FullyConnected (10, calcMode.CUDA), "LS2") \
.addNode ("LS2", LossFunction (lossType.softMaxToCrossEntropy), "Summ") \
\
.addNode ("FC5", FullyConnected (128, calcMode.CUDA), "FC6") \
.addNode ("FC6", FullyConnected (10, calcMode.CUDA), "LS3") \
.addNode ("LS3", LossFunction (lossType.softMaxToCrossEntropy), "Summ") \
\
.addNode ("Summ", LossFunction (lossType.softMaxToCrossEntropy), "Output")
.............
CIFAR-10
Here I had to turn on batchNorm. This grid learns up to 50% accuracy over 1000 iterations, batch 100.
This code turned out:
sn :: Net snet;
snet.addNode ("Input", sn :: Input (), "C1")
.addNode ("C1", sn :: Convolution (15, -1, sn :: calcMode :: CUDA, sn :: batchNormType :: beforeActive), "C2")
.addNode ("C2", sn :: Convolution (15, 0, sn :: calcMode :: CUDA, sn :: batchNormType :: beforeActive), "P1")
.addNode ("P1", sn :: Pooling (sn :: calcMode :: CUDA), "C3")
.addNode ("C3", sn :: Convolution (25, -1, sn :: calcMode :: CUDA, sn :: batchNormType :: beforeActive), "C4")
.addNode ("C4", sn :: Convolution (25, 0, sn :: calcMode :: CUDA, sn :: batchNormType :: beforeActive), "P2")
.addNode ("P2", sn :: Pooling (sn :: calcMode :: CUDA), "C5")
.addNode ("C5", sn :: Convolution (40, -1, sn :: calcMode :: CUDA, sn :: batchNormType :: beforeActive), "C6")
.addNode ("C6", sn :: Convolution (40, 0, sn :: calcMode :: CUDA, sn :: batchNormType :: beforeActive), "P3")
.addNode ("P3", sn :: Pooling (sn :: calcMode :: CUDA), "FC1")
.addNode ("FC1", sn :: FullyConnected (2048, sn :: calcMode :: CUDA, sn :: batchNormType :: beforeActive), "FC2")
.addNode ("FC2", sn :: FullyConnected (128, sn :: calcMode :: CUDA, sn :: batchNormType :: beforeActive), "FC3")
.addNode ("FC3", sn :: FullyConnected (10, sn :: calcMode :: CUDA), "LS")
.addNode ("LS", sn :: LossFunction (sn :: lossType :: softMaxToCrossEntropy), "Output");
I think it is clear that you can substitute any classes of pictures.
U-Net Tyni
The last example. Simplified the native U-Net for demonstration.
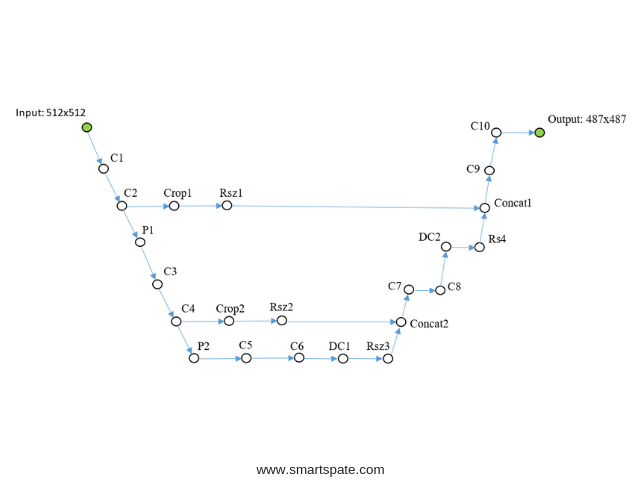
I’ll explain a little bit: DC1 layers … – reverse convolution, Concat1 layers … – layers of the addition of channels,
Rsz1 … – are used to match the number of channels in the reverse step, because an error on the sum of the channels comes back from the Concat layer.
C ++ code:
sn :: Net snet;
snet.addNode ("In", sn :: Input (), "C1")
.addNode ("C1", sn :: Convolution (10, -1, sn :: calcMode :: CUDA), "C2")
.addNode ("C2", sn :: Convolution (10, 0, sn :: calcMode :: CUDA), "P1 Crop1")
.addNode ("Crop1", sn :: Crop (sn :: rect (0, 0, 487, 487)), "Rsz1")
.addNode ("Rsz1", sn :: Resize (sn :: diap (0, 10), sn :: diap (0, 10)), "Conc1")
.addNode ("P1", sn :: Pooling (sn :: calcMode :: CUDA), "C3")
.addNode ("C3", sn :: Convolution (10, -1, sn :: calcMode :: CUDA), "C4")
.addNode ("C4", sn :: Convolution (10, 0, sn :: calcMode :: CUDA), "P2 Crop2")
.addNode ("Crop2", sn :: Crop (sn :: rect (0, 0, 247, 247)), "Rsz2")
.addNode ("Rsz2", sn :: Resize (sn :: diap (0, 10), sn :: diap (0, 10)), "Conc2")
.addNode ("P2", sn :: Pooling (sn :: calcMode :: CUDA), "C5")
.addNode ("C5", sn :: Convolution (10, 0, sn :: calcMode :: CUDA), "C6")
.addNode ("C6", sn :: Convolution (10, 0, sn :: calcMode :: CUDA), "DC1")
.addNode ("DC1", sn :: Deconvolution (10, sn :: calcMode :: CUDA), "Rsz3")
.addNode ("Rsz3", sn :: Resize (sn :: diap (0, 10), sn :: diap (10, 20)), "Conc2")
.addNode ("Conc2", sn :: Concat ("Rsz2 Rsz3"), "C7")
.addNode ("C7", sn :: Convolution (10, 0, sn :: calcMode :: CUDA), "C8")
.addNode ("C8", sn :: Convolution (10, 0, sn :: calcMode :: CUDA), "DC2")
.addNode ("DC2", sn :: Deconvolution (10, sn :: calcMode :: CUDA), "Rsz4")
.addNode ("Rsz4", sn :: Resize (sn :: diap (0, 10), sn :: diap (10, 20)), "Conc1")
.addNode ("Conc1", sn :: Concat ("Rsz1 Rsz4"), "C9")
.addNode ("C9", sn :: Convolution (10, 0, sn :: calcMode :: CUDA), "C10");
sn :: Convolution convOut (1, 0, sn :: calcMode :: CUDA);
convOut.act = sn :: active :: sigmoid;
snet.addNode ("C10", convOut, "Output");
Full code and images are here.
Open source math like this.
All layers tested on MNIST, TF served as a benchmark for estimating errors.
What’s next
The library will not grow in width, that is, no OpenCV, sockets and so on, so as not to inflate.
The library interface will not be changed/expanded, I will not say that in general and never, but last.
Only in depth: I will do the calculation on OpenCL, the interface for C #, the RNN network can be …
I think it makes no sense to add MKL because the network is a bit deeper – it’s still faster on a video card, and the average performance map is not a deficit at all.
- Import/export of scales with other frameworks – via Python (not yet implemented). The roadmap will be if interest arises from people.
Who can support the code, please? But there are limitations to not break the current architecture.
The interface for a python can be expanded to impossibility, also docks and examples are necessary.
To install from Python:
- pip install libskynet – CPU
- pip install libskynet-cu – CPU + CUDA9.2
- pip install libskynet-cudnn – CPU + cuDNN7.3.1
If your network is not deep, use the CPU + CUDA implementation; memory consumption is orders of magnitude smaller compared to cuDNN.
- Wiki user guide
- The software is distributed freely, MIT license.


{kind=link}