
How Neural Networking Will Impact On Our Lives In The Future!
The article consists of two parts:
- A brief description of some network architectures for detecting objects in an image and image segmentation with links to resources that are most understandable to me. I tried to choose video explanations and preferably in Russian.
- The second part is an attempt to understand the direction of the development of neural network architectures. And technologies based on them.
It all started with the fact that we made two demo applications for classifying and detecting objects on an Android phone:
- Back-end demo, when data is processed on the server and transferred to the phone. Classification of images (image classification) of three types of bears: brown, black and teddy.
- Front-end demo when data is processed on the phone itself. Object detection of three types: hazelnuts, figs, and dates.
There is a difference between the tasks of classifying images, detecting objects in an image, and segmenting images. Therefore, there was a need to find out which neural network architectures detect objects in images and which ones can segment. I found the following examples of architectures with the most understandable links to resources for me:
- A series of architectures based on R-CNN (Regions with Convolution Neural Networks features): R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN. To detect an object in an image using the Region Proposal Network (RPN) mechanism, limited regions are allocated. Initially, the slower Selective Search mechanism was used instead of the RPN. Then, the selected limited regions are fed to the input of a conventional neural network for classification. In the architecture of R-CNN, there are explicit “for” cycles of enumeration over limited regions, for a total of up to 2000 runs through the internal AlexNet network. Due to explicit “for” loops, the speed of image processing slows down. The number of explicit cycles runs through the internal neural network, decreases with each new version of the architecture, and dozens of other changes are carried out to increase speed and to replace the task of detecting objects with the segmentation of objects in Mask R-CNN.
- YOLO (You Only Look Once) is the first neural network that recognizes objects in real-time on mobile devices. Distinctive feature: distinguishing objects in one run (just look once). That is, there are no explicit “for” loops in the YOLO architecture, which is why the network is fast. For example, this analogy: in NumPy, when dealing with matrices, there are also no explicit “for” loops, which in NumPy are implemented at lower levels of architecture through the programming language C. YOLO uses a grid of predefined windows. So that the same object is not detected repeatedly, the coefficient of overlapping windows is used (IoU, Intersection over Union). This architecture works in a wide range and has high robustness: the model can be trained in photographs, but at the same time work well in painted paintings.
- SSD (Single Shot MultiBox Detector) – the most successful “hacks” of the YOLO architecture (for example, non-maximum suppression) are used and new ones are added to make the neural network faster and more accurate. Distinctive feature: distinguishing objects in one run using a given grid of windows (default box) on the pyramid of images. The pyramid of images is encoded in convolution tensors during successive convolution and pooling operations (with the max-pooling operation, the spatial dimension decreases). In this way, both large and small objects are determined in a single network run.
- MobileSSD (MobileNetV2 + SSD) is a combination of two neural network architectures. The first MobileNetV2 network is fast and increases recognition accuracy. MobileNetV2 is used instead of VGG-16, which was originally used in the original article. The second SSD network determines the location of objects in the image.
- SqueezeNet is a very small but accurate neural network. By itself, it does not solve the problem of detecting objects. However, it can be used with a combination of different architectures. And be used on mobile devices. A distinctive feature is that the data is first compressed to four 1 × 1 convolutional filters, and then expanded to four 1 × 1 and four 3 × 3 convolutional filters. One such iteration of data compression-expansion is called the “Fire Module”.
- DeepLab (Semantic Image Segmentation with Deep Convolutional Nets) – segmentation of objects in the image. A distinctive feature of the architecture is a diluted convolution, which preserves spatial resolution. This is followed by the stage of post-processing the results using a graphical probabilistic model (conditional random field), which allows you to remove small noise in the segmentation and improve the quality of the segmented image. Behind the formidable name “graphical probabilistic model” is the usual Gaussian filter, which is approximated by five points.
- I tried to figure out the RefineDet device (Single-Shot Refinement Neural Network for Object Detection) but understood a little.
- I also looked at how the attention technology works: video1, video2, video3. A distinctive feature of the “attention” architecture is the automatic allocation of regions of increased attention to the image (RoI, Regions of Interest) using a neural network called the Attention Unit. Regions of increased attention are similar to limited regions (bounding boxes), but unlike them, they are not fixed on the image and may have blurry borders. Then, from the regions of increased attention, features (features) are distinguished that are “fed” to recurrent neural networks with LSDM, GRU, or Vanilla RNN architectures. Recursive neural networks are able to analyze the relationship of signs in a sequence. Recursive neural networks were originally used to translate text into other languages, and now to translate images into text and text into images.
As I studied these architectures, I realized that I didn’t understand anything. And the point is not that my neural network has problems with the attention mechanism. Creating all of these architectures is like some sort of huge hackathon where authors compete in hacks. The hack is a quick solution to a difficult software task. That is, between all these architectures there is no visible and understandable logical connection. All that unites them is a set of the most successful hacks that they borrow from each other, plus a common convolution operation with feedback (reverse propagation of error, backpropagation). No systemic thinking! It is not clear what to change and how to optimize existing achievements.
As a result of the lack of a logical connection between hacks, they are extremely difficult to remember and put into practice. This is fragmented knowledge. In the best case, several interesting and unexpected moments are remembered, but most of what is understood and incomprehensible disappears from memory within a few days. It will be good if in a week I recall at least the name of architecture. But it took several hours and even days of working time to read articles and watch review videos!
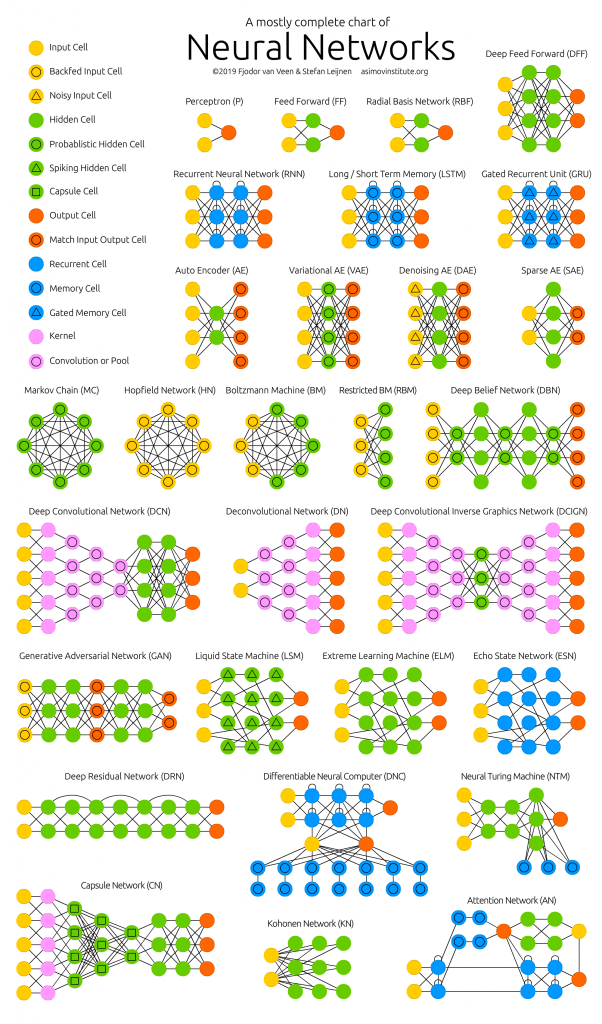
Most authors of scientific articles, in my personal opinion, do everything possible so that even this fragmented knowledge is not understood by the reader. But the participle in ten-line sentences with formulas taken “from the ceiling” is a topic for a separate article (publish or perish problem).
For this reason, it became necessary to systematize information on neural networks and, thus, increase the quality of understanding and memorization. Therefore, the main topic of analysis of individual technologies and architectures of artificial neural networks was the following task: to find out where all this is moving, and not the device of any particular neural network separately.
Where is all this going? The main results:
- The number of startups in the field of machine learning has fallen sharply in the past two years. Possible reason: “neural networks have ceased to be something new.”
- Everyone will be able to create a working neural network to solve a simple problem. To do this, take the finished model from the “model zoo” and train the last layer of the neural network (transfer learning) on the finished data from Google Dataset Search or from 25 thousand Kaggle datasets in the free Jupyter Notebook cloud.
- Large manufacturers of neural networks began to create “model zoos” (model zoo). Using them, you can quickly make a commercial application: TF Hub for TensorFlow, MMDetection for PyTorch, Detectron for Caffe2, chained-model zoo for Chainer and others.
- Real-time neural networks on mobile devices. 10 to 50 frames per second.
- The use of neural networks in phones (TF Lite), in browsers (TF.js) and in household items (IoT, Internet of Things). Especially in phones that already support neural networks at the hardware level (neuroaccelerators).
- “Each device, clothing, and possibly even food will have an IP-v6 address and communicate with each other” – Sebastian Trun.
- The increase in machine learning publications has begun to exceed Moore’s law (doubling every two years) since 2015. Obviously, article analysis neural networks are needed.
- The following technologies are gaining popularity:
- PyTorch – Popularity is growing rapidly and seems to overtake TensorFlow.
- Automatic selection of AutoML hyperparameters – popularity is growing smoothly.
- The gradual decrease in accuracy and increase in computation speed: fuzzy logic, boosting algorithms, inaccurate (approximate) calculations, quantization (when the weights of a neural network are converted to integers and quantized), neuroaccelerators.
- Translation of image into text and text into the image.
- Creating three-dimensional objects from video, now in real-time.
- The main thing in DL is a lot of data, but collecting and marking them up is not easy. Therefore, automated annotation for neural networks using neural networks is developing.
Gradually, a new ML/DL programming methodology (Machine Learning & Deep Learning) appears, which is based on the presentation of the program as a collection of trained neural network models
However, the “theory of neural networks” did not appear, within the framework of which one can think and work systemically. What is now called “theory” is actually experimental, heuristic algorithms.
Links to resources:
- A general list of courses and articles that I went through and that I would like to go through.
- Courses and videos for beginners, with which it is worth starting to study neural networks. Plus the brochure “Introduction to machine learning and artificial neural networks.”
- Useful tools where everyone will find something interesting for themselves.
- The video channels for the analysis of scientific articles on Data Science turned out to be extremely useful. Find, subscribe to them and pass links to your colleagues and me too. Examples:
- Two Minute Papers
- Henry AI Labs
- Yannic Kilcher
- CodeEmporium
- Chengwei Zhang aka Tony607 blog with step by step instructions and open source.


{kind=link}